If you’ve ever built anything with local LLMs — whether it’s a personal assistant in Ollama, a coding buddy in LM Studio, or a custom agent — you’ve probably hit the same wall: the model forgets everything the moment the session ends.
You spend an hour teaching it about your project structure, your preferred coding style, or your weird dietary restrictions… and next time you fire it up? It’s back to square one. Stateless. Blank slate. Infuriating.
That’s where memlayer comes in.
memlayer (lowercase “m”, because cool projects don’t need capitalization) is a brand-new, open-source Python package that adds plug-and-play, persistent, intelligent long-term memory to any LLM workflow — especially local ones.
– GitHub: https://github.com/divagr18/memlayer
– Install: `pip install memlayer`
– No servers, no cloud APIs, no massive frameworks required.
It’s designed from the ground up for the local LLM crowd, and after playing with it for a few days, I’m genuinely excited. Here’s why.
What Makes memlayer Different?
There are already memory solutions out there (Mem0, MemGPT-inspired stuff, LangGraph persistence, etc.), but most assume you’re okay with:
– Calling OpenAI/Anthropic for every memory operation
– Setting up vector DBs + graph DBs + key-value stores manually
– Adopting a heavy agent framework
memlayer says “no thanks” to all that. Its philosophy:
– Local-first – Works offline with any HuggingFace embedding model.
– Lightweight – Pure Python, minimal dependencies.
– Intelligent filtering – Optional ML-based “salience gate” that asks “Is this actually worth remembering?” before storing junk.
– Hybrid retrieval – Vector search *plus* optional knowledge-graph traversal for relational recall (e.g., “Who introduced me to Alice again?”).
– Three search tiers – Fast keyword/vector, deeper hybrid, or let the LLM decide automatically.
The result? Your LLM starts behaving like it actually knows you across sessions.
Real-World Use Cases That Already Feel Addictive
1. The Personal Assistant That Actually Remembers You
– Tell it once: “My name is Alex, I hate cilantro, and I code in Python with black formatting.”
– Next day: “Plan a dinner recipe” → It skips cilantro and formats code snippets perfectly.
– Bonus: It builds a little knowledge graph, so later “Who do I know that lives in Berlin?” actually works.
2. Long-Running Coding Projects
– You’re hacking on a FastAPI + React app for weeks.
– MemLayer quietly stores architecture decisions, env var locations, weird bugs you fixed.
– Mid-session: “Why was authentication breaking again?” → Instant recall with relevant code context.
3. Research / Reading Companion
– Feed it papers, blog posts, or book chapters over time.
– It consolidates insights, tracks contradictions, and answers questions like “What did that one paper say about retrieval augmented generation vs. fine-tuning?”
4. RPGs, Worldbuilding, or Creative Writing
– Build persistent worlds where NPCs remember past interactions.
– “The innkeeper still distrusts me because I stole that apple three sessions ago” — yes, please.
5. Customer Support Bots (Local Edition)
– Run a private support bot for your indie app.
– Each user gets their own memory store. No data leaves your machine.
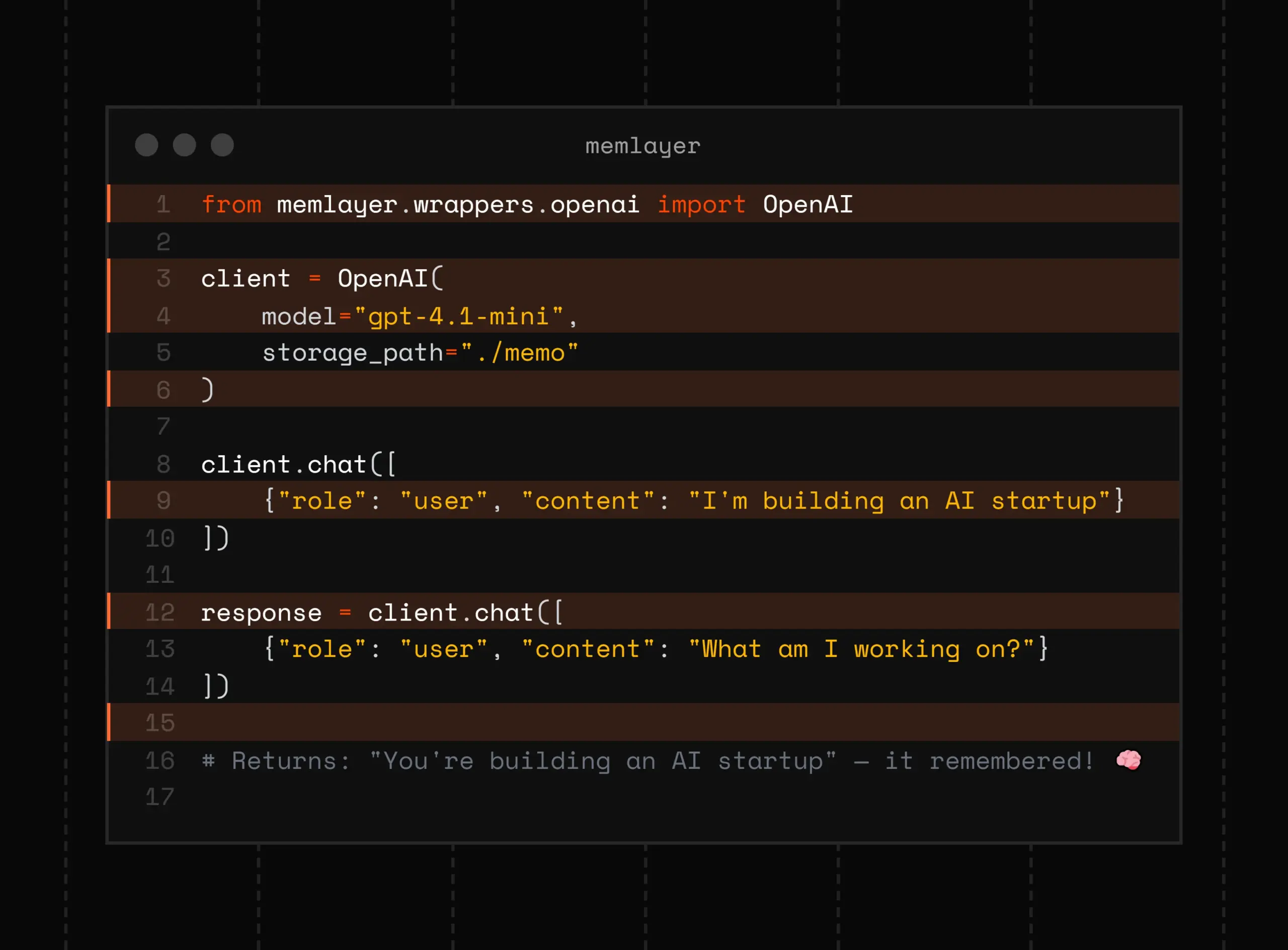
from memlayer import MemLayerClient
from ollama import Client # or openai, anthropic, etc.
# Initialize once
client = MemLayerClient(
user_id="alex_local",
embedding_model="nomic-embed-text", # local HF model
storage="chromadb" # or "networkx" for pure-graph
)
# Wrap your LLM calls — that's it!
response = client.chat([
{"role": "user", "content": "Hi, remember me? I hate olives."}
])
Later, even after restarting everything:
response = client.chat([
{"role": "user", "content": "Suggest a pizza topping"}
])
# → "How about pepperoni and mushrooms? (Skipping olives — you mentioned you hate them!)"
My Hot Takes After Using It
- The salience gate is genius. Without it, memory bloat is real. With it, my store stayed clean even after hours of rambling.
- Hybrid search shines when facts are relational. Pure vector search would miss “Bob works for the company that Alice founded.”
- Performance is surprisingly snappy on a laptop — even with local embeddings.
- The “automatic” search tier (where the LLM picks the depth) feels like having a tiny brain inside your bigger brain.
Minor Caveats (Because Honesty)
- Still early days (only a few weeks old as of this writing).
- You need a decent embedding model running locally for full offline mode.
- Graph features are optional and add a tiny bit of complexity.
But honestly? For something this powerful and this simple, these are nitpicks.
Final Thought
If you’re in the local LLM ecosystem and you’ve been jealous of how “stateful” the cloud models feel lately… stop being jealous.
Go install memlayer right now.
Your future self (and your LLM) will thank you.
pip install memlayer
GitHub: https://github.com/divagr18/memlayer
Go forth and give your models a memory they’ll never forget. 🚀